本篇文章给大家分享的是有关如何解析 HBase 冷热分离技术原理,丸趣 TV 小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着丸趣 TV 小编一起来看看吧。
前言
HBase 是当下流行的一款海量数据存储的分布式数据库。往往海量数据存储会涉及到一个成本问题,如何降低成本。常见的方案就是通过冷热分离来治理数据。冷数据可以用更高的压缩比算法(ZSTD),更低副本数算法(Erasure Coding),更便宜存储设备(HDD,高密集型存储机型)。
HBase 冷热分离常见解决方案 1. 主备集群
备(冷)集群用更廉价的硬件,主集群设置 TTL,这样当数据热度退去,冷数据自然只在冷集群有。
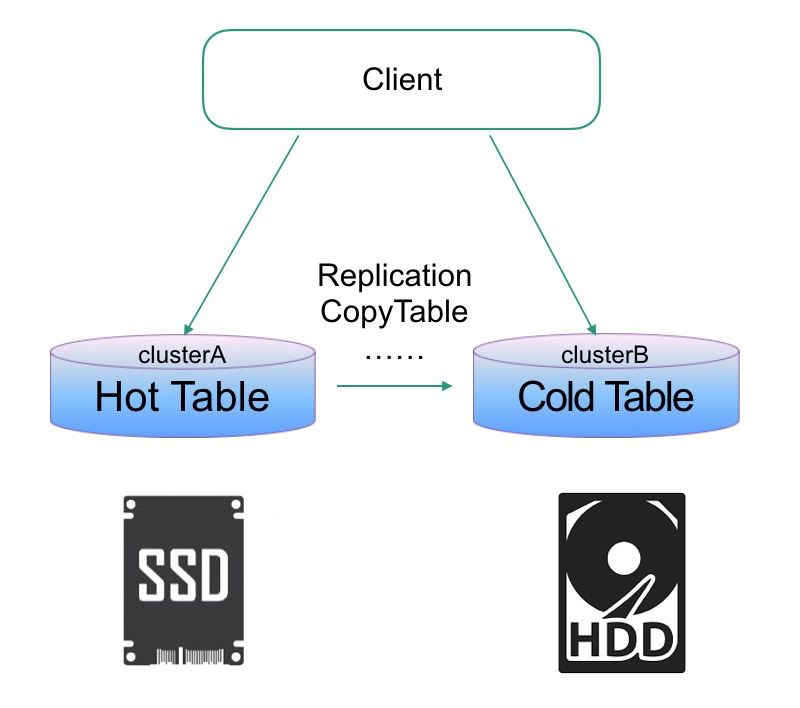
优点:方案简单,现成内核版本都能搞
缺点:维护开销大,冷集群 CPU 存在浪费
1.x 版本的 HBase 在不改内核情况下,基本只能有这种方案。
2.HDFS Archival Storage + HBase CF-level Storage Policy
需要在 2.x 之后的版本才能使用。结合 HDFS 分层存储能力 + 在 Table 层面指定数据存储策略,实现同集群下,不同表数据的冷热分离。
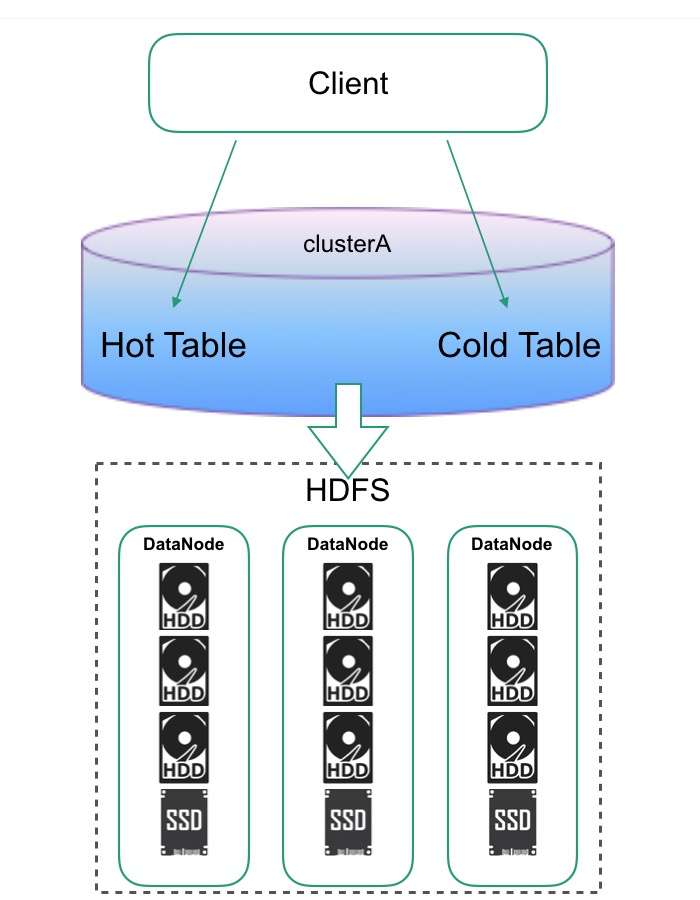
优点:同一集群冷热分离,维护开销少,更灵活的配置不同业务表的策略
缺点:磁盘配比是个很大的问题,不同业务冷热配比是不一样的,比较难整合在一起,一旦业务变动,集群硬件配置是没法跟着变的。
云 HBase 冷热分离解决方案
上述 2 套方案都不是最好的方案,对于云上来说。第一套方案就不说了,客户搞 2 个集群,对于数据量不大的客户其实根本降不了成本。第二套方案,云上客户千千万,业务各有各样,磁盘配置是很难定制到合适的状态。
云上要做 cloud native 的方案,必须满足同集群下,极致的弹性伸缩,才能真正意义上做到产品化。云上低成本,弹性存储,只有 OSS 了。所以很自然的想到如下架构:
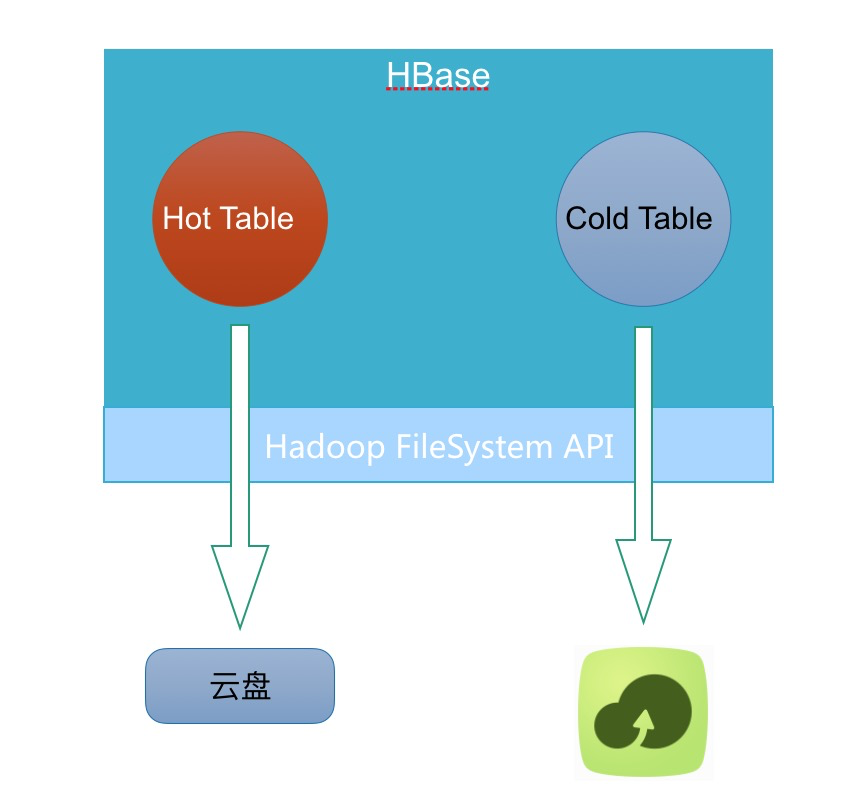
实现这样的架构,最直接的想法是直接改 HBase 内核:1)增加冷表数据标记 2)根据标记增加写 OSS 的 IO 路径。
这样做的缺陷非常明显,你的外部系统(如:备份恢复,数据导入导出)很难兼容这些改动,他们需要感知哪些是冷文件得去 OSS 哪个位置读,哪些是热文件得去部署在云盘上的 HDFS 上读。这些本质上都是一些重复的工作,所以从架构设计角度来看必须抽象出一层。这一层能读写 HDFS 文件,读写 OSS 文件,感知冷热文件。这一层也就是我最后设计出的 ApsaraDB FileSystem,实现了 Hadoop FileSystem API。对于 HBase,备份恢复,数据导入导出等系统只要替换原先 FileSystem 的实现即可获得冷热分离的功能。
下面将详细阐述,这套 FileSystem 设计的细节与难点。
ApsaraDB FileSystem 设计核心难点 A1.OSS 并非文件系统
OSS 并不是一个真正意义上的文件系统,它仅仅是两级映射 bucket/object,所以它是对象存储。你在 OSS 上看到类似这样一个文件:
/root/user/gzh/file。你会以为有 3 层目录 + 1 个文件。实际上只有一个对象,这个对象的 key 包含了 / 字符罢了。
这么带来的一个问题是,你要想在其上模拟出文件系统,你必须先能创建目录。很自然想到的是用 / 结尾的特殊对象代表目录对象。Hadoop 社区开源的 OssFileSystem 就是这么搞的。有了这个方法,就能判断到底存不存在某个目录,能不能创建文件,不然会凭空创建出一个文件,而这个文件没有父目录。
当然你这么做依然会有问题。除了开销比较大(创建深层目录多次 HTTP 请求 OSS),最严重的是正确性的问题。试想一下下面这个场景:
把目录 /root/user/source rename 成 /root/user/target。这个过程除了该目录,它底下的子目录,子目录里的子文件都会跟着变。类似这样:/root/user/source/file = /root/user/target/file。这很好理解,文件系统就是一颗树,你 rename 目录,实际是把某颗子树移动到另一个节点下。这个在 NameNode 里的实现也很简单,改变下树结构即可。
但是如果是在 OSS 上,你要做 rename,那你不得不递归遍历 /root/user/source 把其下所有目录对象,文件对象都 rename。因为你没法通过移动子树这样一个简单操作一步到位。这里带来的问题就是,假设你递归遍历到一半,挂了。那么就可能会出现一半目录或文件到了目标位置,一半没过去。这样 rename 这个操作就不是原子的了,本来你要么 rename 成功,整个目录下的内容到新的地方,要么没成功就在原地。所以正确性会存在问题,像 HBase 这样依赖 rename 操作将临时数据目录移动到正式目录来做数据 commit,就会面临风险。
2.OSS rename 实则是数据拷贝
前面我们提到了 rename,在正常文件系统中应该是一个轻量级的,数据结构修改操作。但是 OSS 并没有 rename 这个操作实际上,rename 得通过 CopyObject + DeleteObject 两个操作完成。首先是 copy 成目标名字,然后 delete 掉原先的 Object。这里有 2 个明显的问题,一个是 copy 是深度拷贝开销很大,直接会影响 HBase 的性能。另一个是 rename 拆分成 2 个操作,这 2 个操作是没法在一个事物里的,也就是说:可能存在 copy 成功,没 delete 掉的情况,此时你需要回滚,你需要 delete 掉 copy 出来的对象,但是 delete 依然可能不成功。所以 rename 操作本身实现上,正确性就难以保证了。
解决核心难点 A
解决上面 2 个问题,需要自己做元数据管理,即相当于自己维护一个文件系统树,OSS 上只放数据文件。而因为我们环境中仍然有 HDFS 存储在(为了放热数据),所以直接复用 NameNode 代码,让 NodeNode 帮助管理元数据。所以整体架构就出来了:
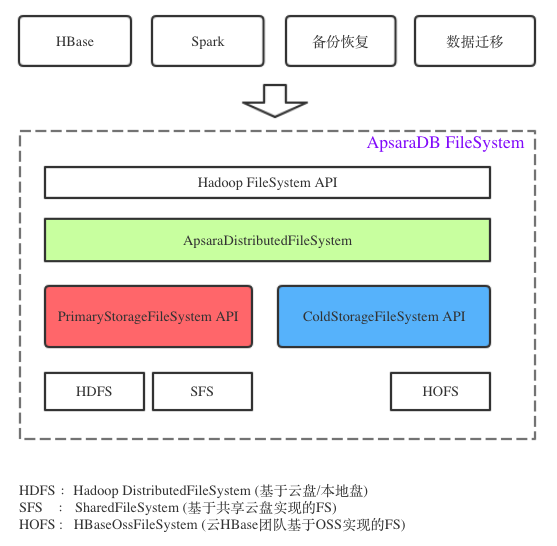
ApsaraDB FileSystem(以下简称 ADB FS)将云端存储分为:主存(PrimaryStorageFileSystem)和 冷存(ColdStorageFileSystem)。由 ApsaraDistributedFileSystem 类(以下简称 ADFS)负责管理这两类存储文件系统,并且由 ADFS 负责感知冷热文件。
ApsaraDistributedFileSystem: 总入口,负责管理冷存和主存,数据该从哪里读,该写入哪里(ADFS)。
主存:PrimaryStorageFileSystem 默认实现是 DistributedFileSystem(HDFS)
冷存:ColdStorageFileSystem 默认实现是 HBaseOssFileSystem(HOFS),基于 OSS 实现的 Hadoop API 文件系统,可以模拟目录对象单独使用,也可以只作为冷存读写数据,相比社区版本有针对性优化,后面会讲。
具体,NameNode 如何帮助管理冷存上的元数据,很简单。ADFS 在主存上创建同名索引文件,文件内容是索引指向冷存中对应的文件。实际数据在冷存中,所以冷存中的文件有没有目录结构无所谓,只有一级文件就行。我们再看下一 rename 操作过程,就明白了,rename 目录的场景也同理,直接在 NameNode 中 rename 就行。对于热文件,相当于全部代理 HDFS 操作即可,冷文件要在 HDFS 上创建索引文件,然后写数据文件到 OSS,然后关联起来。
核心难点 B
引入元数据管理解决方案,又会遇到新的问题:是索引文件和冷存中数据文件一致性问题。
我们可能会遇到如下场景:
主存索引文件存在,冷存数据文件不存在
冷存数据文件存在,主存索引文件不存住
主存索引文件信息不完整,无法定位冷存数据文件
先排除 BUG 或者人为删除数据文件因素,上诉 3 种情况都会由于程序 crash 产生。也就是说我们要想把法,把生成索引文件,写入并生成冷数据文件,关联,这 3 个操作放在一个事物里。这样才能具备原子性,才能保证要么创建冷文件成功,那么索引信息是完整的,也指向一个存在的数据文件。要么创建冷文件失败(包括中途程序 crash),永远也见不到这个冷文件。
解决核心难点 B
核心思想是利用主存的 rename 操作,因为主存的 rename 是具备原子性的。我们先在主存的临时目录中生产索引文件,此时索引文件内容已经指向冷存中的一个路径(但是实际上这个路径的数据文件还没开始写入)。在冷存完成写入,正确 close 后,那么此时我们已经有完整且正确的索引文件 数据文件。然后通过 rename 一把将索引文件改到用户实际需要写入到目标路径,即可。
如果中途进程 crash,索引文件要么已经 rename 成功,要么索引文件还在临时目录。在临时目录我们认为写入没有完成,是失败的。然后我们通过清理线程,定期清理掉 N 天以前临时目录的文件即可。所以一旦 rename 成功,那目标路径上的索引文件一定是完整的,一定会指向一个写好的数据文件。
为什么我们需要先写好路径信息在索引文件里?因为如果先写数据文件,在这个过程中 crash 了,那我们是没有索引信息指向这个数据文件的,从而造成类似“内存泄漏”的问题。
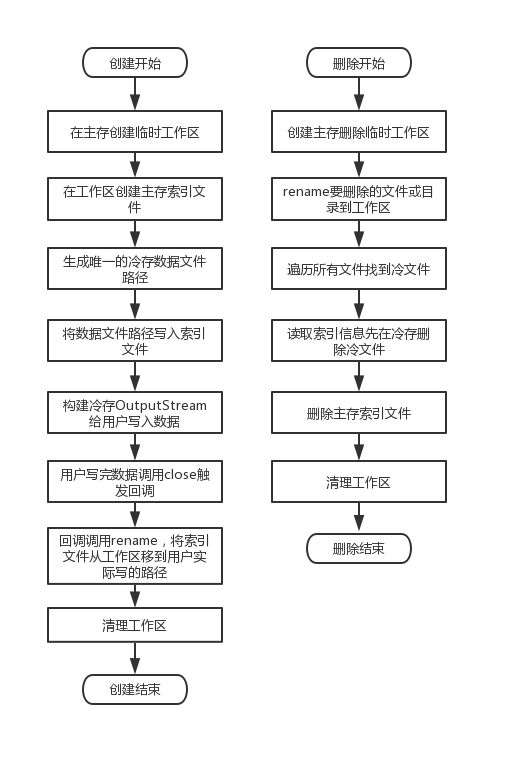
冷热文件标记
对于主存,需要实现给文件冷热标记的功能,通过标记判断要打开怎样的数据读写流。这点 NameNode 可以通过给文件设置 StoragePolicy 实现。这个过程就很简单了,不详细赘述,下面说 HBaseOssFileSystem 写入优化设计。
HBaseOssFileSystem 写入优化
在说 HOFS 写设计之前,我们先要理解 Hadoop 社区版本的 OssFileSystem 设计(这也是社区用户能直接使用的版本)。
社区版本写入设计
Write - OutputStream - disk buffer(128M) - FileInputStream - OSS这个过程就是先写入磁盘,磁盘满 128M 后,将这 128M 的 block 包装成 FileInputStream 再提交给 OSS。这个设计主要是考虑了 OSS 请求成本,OSS 每次请求都是要收费的,但是内网流量不计费。如果你 1KB 写一次,费用就很高了,所以必须大块写。而且 OSS 大文件写入,设计最多让你提交 10000 个 block(OSS 中叫 MultipartUpload),如果 block 太小,那么你能支持的最大文件大小也是受限。
所以要攒大 buffer,另外一个因素是 Hadoop FS API 提供的是 OutputStream 让你不断 write。OSS 提供的是 InputStream,让你提供你要写入内容,它自己不断读取。这样你必然要通过一个 buffer 去转换。
这里会有比较大的一个问题,就是性能慢。写入磁盘,再读取磁盘,多了这么两轮会比较慢,虽然有 PageCache 存在,读取过程不一定有 IO。那你肯定想,用内存当 buffer 不就好了。内存当 buffer 的问题就是前面说的,有费用,所以 buffer 不能太小。所以你每个文件要开 128M 内存,是不可能的。更何况当你提交给 OSS 的时候,你要保证能继续写入新数据,你得有 2 块 128M 内存滚动,这个开销几乎不能接受。
HBaseOssFileSystem 写入设计
我们既要解决费用问题,也要解决性能问题,同时要保证开销很低,看似不可能,那么怎么做呢?
这里要利用的就是这个 InputStream,OSS 让你提供 InputStream,并从中读取你要写入的内容。那么我们可以设计一个流式写入,当我传入这个 InputStream 给 OSS 的时候,流中并不一定得有数据。此时 OSS 调 read 读取数据会 block 在 read 调用上。等用户真的写入数据,InputStream 中才会有数据,这时候 OSS 就能顺利读到数据。当 OSS 读了超过 128M 数据时候,InputStream 会自动截断,返回 EOF,这样 OSS 会以为流已经结束了,那么这块数据就算提交完成。
所以我们本质只要开发这么一个特殊的 InputStream 即可。用户向 Hadoop API 提供的 OutputStream 中写入数据,数据每填满一个 page(2M)就发给 InputStream 让其可读取。OuputStream 相当于生产者,InputStream 相当于消费者。这里的内存开销会非常低,因为生产者速度和消费者速度相近时,也就 2 个 page 的开销。最后将这整套实现封装成 OSSOutputStream 类,当用户要写入冷文件时,实际提供的是 OSSOutputStream,这里面就包含了这个特殊 InputStream 的控制过程。
当然实际生产中,我们会对 page 进行控制,每个文件设置最多 4 个 page。并且这 4 个 page 循环利用,减少对 GC 对影响。
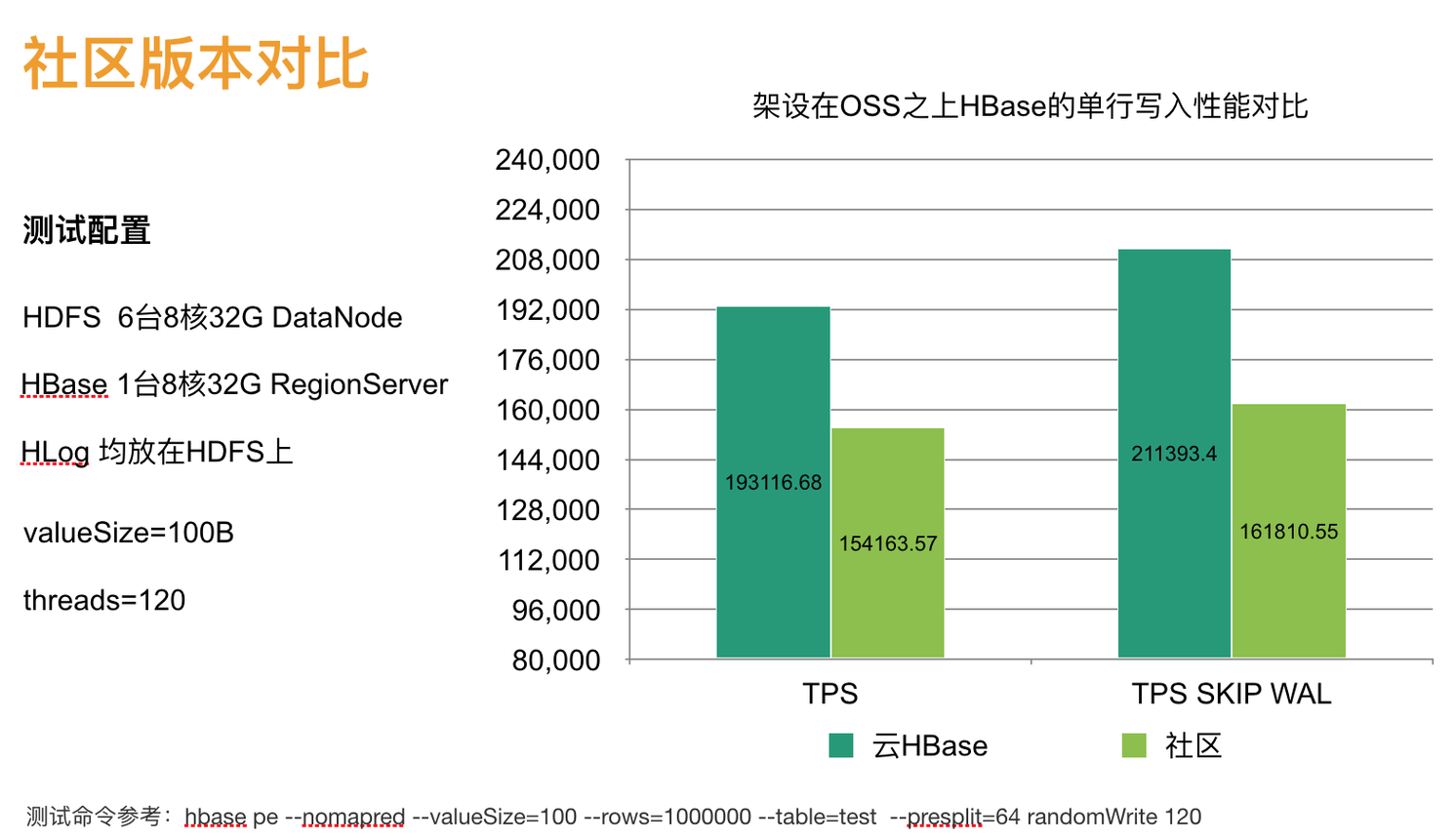
性能对比 1:社区版本 vs 云 HBase 版
因为不用写磁盘,所以写入吞吐可以比社区的高很多,下图为 HBase1.0 上测试结果。在一些大 KV,写入压力更大的场景,实测可以接近 1 倍。这个比较是通过替换 ADFS 冷存的实现 (用社区版本和云 HBase 版本),都避免了 rename 深拷贝问题。如果直接裸用社区版本而不用 ADFS 那性能会差数倍。
性能对比 2:热表 vs 冷表
热表数据在云盘,冷表数据在 OSS。
得益于上述优化,加上冷表 WAL 也是放 HDFS 的,并且 OSS 相对 HBase 来说是大集群(吞吐上限高),冷表的 HDFS 只用抗 WAL 写入压力。所以冷表吞吐反而会比热表略高一点点。
不管怎么说,冷表的写入性能和热表相当了,这样的表现已经相当不错了。基本是不会影响用户灌数据,否则使用冷存后,吞吐掉很多,那意味着要更多机器,那这功能就没什么意义了。
以上就是如何解析 HBase 冷热分离技术原理,丸趣 TV 小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注丸趣 TV 行业资讯频道。










 六了个六
6666
六了个六
6666